Single-model trust is broken in 2026
96% of developers don't fully trust AI-generated code. Only 48% verify systematically. NexaVerify is for the other 52% who know they should — but don't have time.
Single-model review
One LLM returns findings. Some are real. Some are hallucinations. You can't tell which is which — so you either trust everything (waste time on false positives) or ignore everything (miss real bugs).
Multi-provider consensus
Multiple LLMs analyze the same code independently. NexaVerify compares outputs — issues confirmed across providers get higher confidence. Isolated findings get lower. Disagreements are surfaced, not hidden.
Three depths, one workflow
Quick
Fastest sanity pass. Small checks, quick signal.
Balanced ★
Best default. Speed, signal quality, and cost balanced.
Deep
Pre-delivery audits, client work, sensitive code.
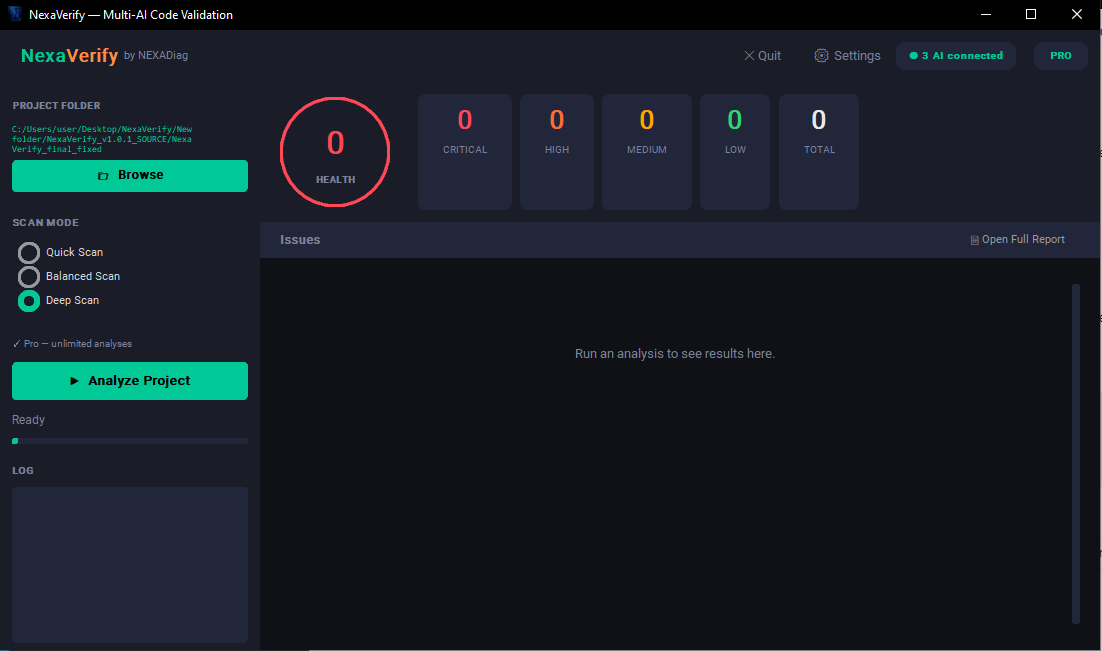
From folder to validated report
Select project. NexaVerify builds a local view: files, chunks, stack, hotspots.
Multiple providers analyze in parallel. Consensus engine filters weak or isolated signals.
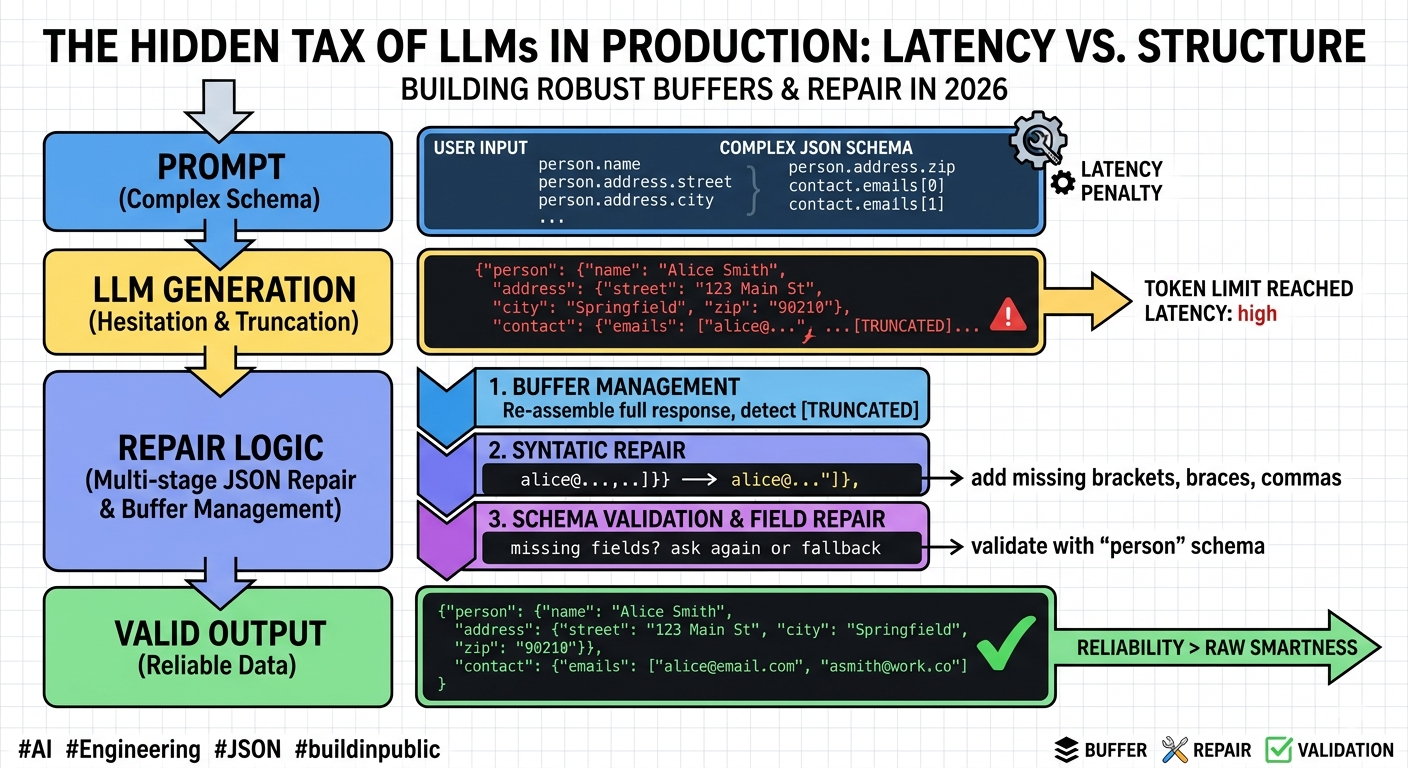
Truncated or malformed LLM responses are automatically repaired — bracket matching, fallback extraction, and structural validation before parsing.
HTML for humans. JSON for automation, archiving, run-to-run diffing.